
The pitch is seductive:
- Point an AI agent at your CRM, your ERP, your marketing automation platform, your support ticketing system.
- Let it pull the data it needs.
- Ask it a question in plain English.
- Get a chart and an answer in thirty seconds.
No warehouse. No pipelines. No semantic layer. No waiting for the data team.
We’ve seen this demo. It works. We also know how this story ends, because we’ve seen earlier versions of it play out: analysts reporting off live JDBC connections to production databases, finance teams building models on raw data extracts in Excel where the logic lives in one person’s head, operations teams pulling CSV dumps and applying ad hoc filters that nobody can reproduce six months later. The tooling is new. The pattern is not. And it does not end well.
Since tools like Claude Code / OpenAI Codex and MCP-based integrations (like MotherDuck’s) became capable enough to do serious analytical work, multiple clients have asked us some version of the same question: “If agents can go straight to the source, why are we still building data infrastructure?” It’s a fair question, and the premise is not wrong. AI agents are gaining the ability to connect directly to systems of record (CRMs, ERPs, HRIS platforms, marketing automation tools, support systems, production databases), query them on demand, and return answers as data visualizations or natural language. But “works in a demo” and “works reliably at enterprise scale” are separated by a gap that is wider than many realize. The infrastructure that fills that gap is precisely the infrastructure some are now proposing to skip.
Our position is straightforward: agents do not eliminate the problems that data infrastructure solves. They amplify them.
The companies building the most capable agents in the world seem to agree. OpenAI runs its internal analytics on Snowflake, dbt, Airflow, and Spark. Both OpenAI and Anthropic operate dedicated ClickHouse clusters at petabyte scale for analytical workloads. They are not bypassing data infrastructure. They are investing heavily in it.
What follows is our reasoning for why. But first, a picture of the two paths.
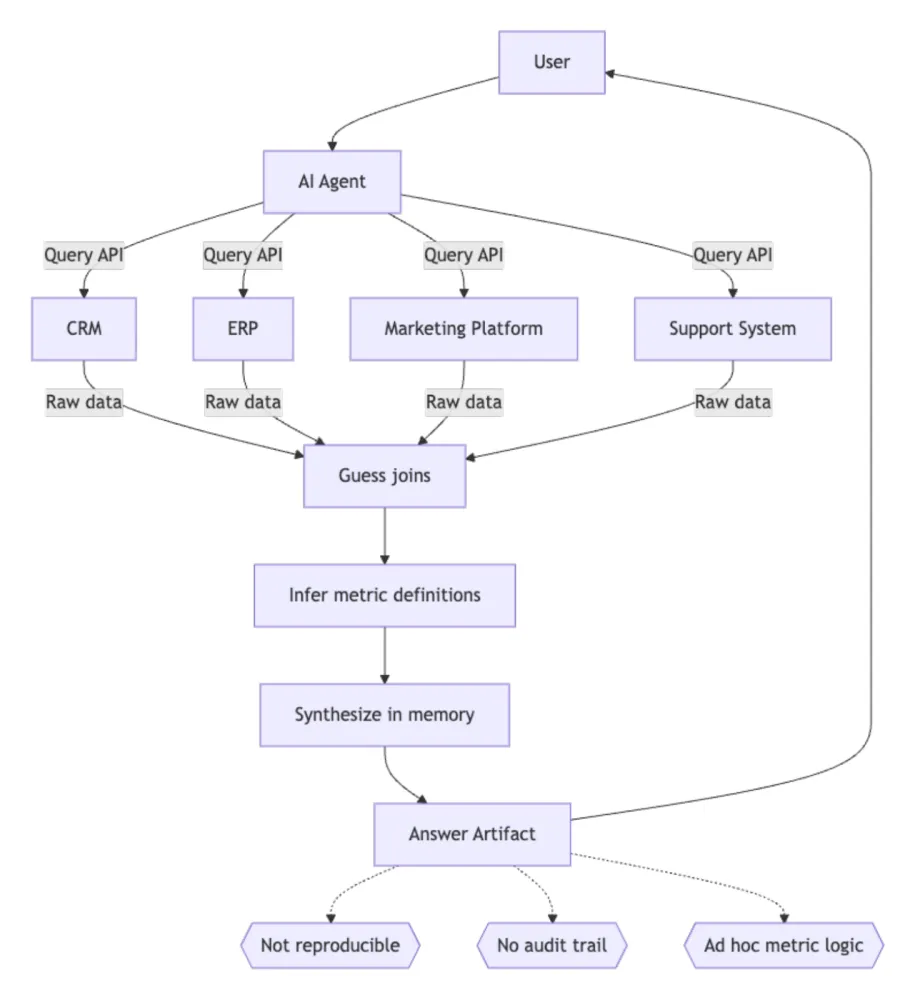
The Ungoverned Path
The agent queries every source system directly, receives raw data with no shared keys or business context, reasons through joins and metric definitions on the fly, and delivers an answer that cannot be reproduced or audited. If the same question is asked tomorrow by a different agent (or the same agent in a different session), the reasoning path may differ and so may the answer.
The Governed Path
Data is extracted, validated, tested, transformed, and served through a semantic layer. The agent queries governed metrics with defined business logic rather than guessing from raw tables. Same question, same agent, very different reliability.
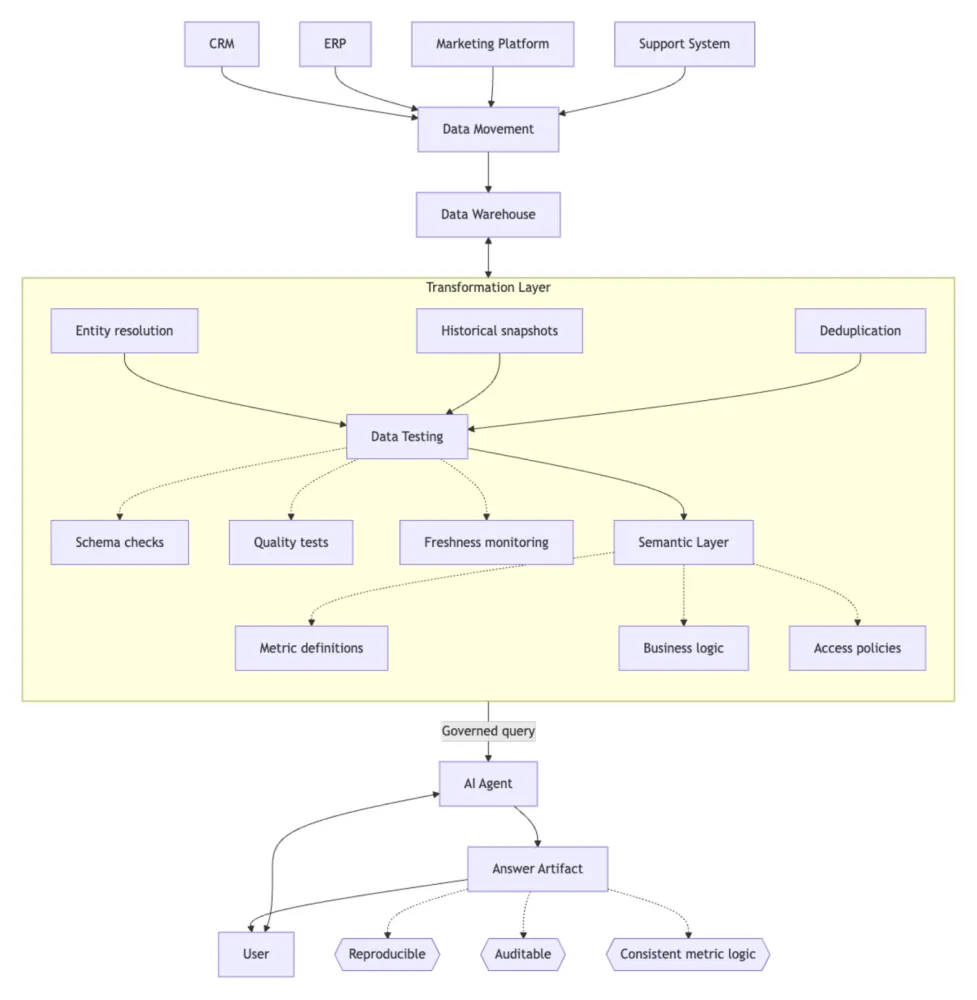
Each layer in the governed path solves a specific problem. Skip one, and the corresponding failure mode shows up in the agent’s output.
The rest of this post walks through why each of these layers matters.
Agents Without Context Produce Wrong Answers
This is the argument that matters most. An AI agent connecting to raw source tables has no understanding of your business logic. It does not know that “revenue” means recognized revenue net of returns in Finance but gross bookings in Sales. It does not know that “active customer” means a customer with at least one order in the trailing 12 months, not a non-churned account. It does not know that your fiscal year starts in April.
Gartner elevated the semantic layer to essential infrastructure in its 2025 Hype Cycle for Analytics and BI because of this problem. Unlike a human analyst, an agent won’t flag ambiguity. It will pick an interpretation and present it with full confidence. If a human analyst struggles without context, an AI agent has no chance.
The problem runs deeper than metric definitions. Every mature data team has years of hard-won knowledge encoded in their transformation logic. “Exclude orders with status=‘test’.” “Ignore the employee_discount flag before March 2024 because it was broken.” “This revenue field double-counts intercompany transfers.” These rules live in the data layer. If your agent is querying raw tables, it inherits every data quality problem that the transformation layer was built to handle.
A semantic layer encodes metric definitions, entity relationships, business rules, and access policies in a single governed model. When agents query through it, rather than around it, they get answers that are consistent, auditable, and aligned with how the organization actually defines its terms. Without it, you get automated confusion at scale.
OpenAI learned this firsthand. Before deploying their own internal data agent to serve 3,500+ employees, they built six distinct context layers on top of their data warehouse, extracting business logic from their dbt models, Airflow DAGs, and Spark jobs. As their team described it: “Meaning lives in code. Pipeline logic captures assumptions, freshness guarantees, and business intent that never surface in SQL or metadata.”
OpenAI is a company founded by software and ML engineers, with all of their data centralized on one platform, and they still needed six layers of context before an agent could reliably answer questions about it. Most companies are not staffed by ML engineers. Most companies have data scattered across a dozen systems acquired over decades, governed by business logic that lives in people’s heads or in tribal documentation. If OpenAI is layering context onto their data using code, everyone else needs to layer it onto theirs using the tools that actually work for businesses operating in the physical world: data warehouses, transformation pipelines, and semantic layers. We cover what to build and in what order in The Context Layer: What to Build, What to Skip, and Where to Start.
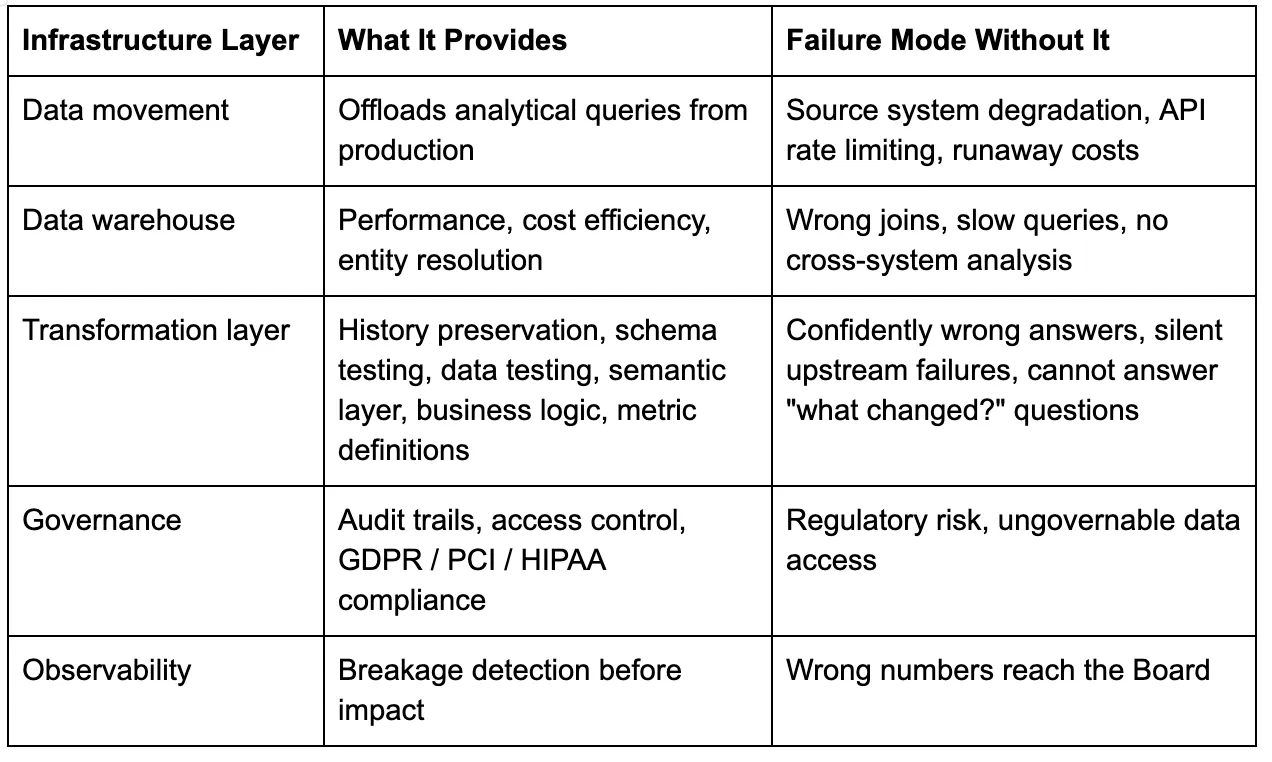
Three Data Problems That Agents Cannot Solve on Their Own
Beyond the semantic layer, there are structural data problems that no amount of model capability will resolve.
Entity resolution. Customer #4521 in your CRM is user_id 89203 in your product database, contact 78331 in your marketing automation platform, and ticket requester “[email protected]” in your support system. Resolving these into a single entity requires identity mapping tables, surrogate keys, fuzzy matching, and often manual curation. This is the core work of data engineering. An agent querying three systems simultaneously has no reliable mechanism to know these records describe the same customer.
Historical data. Source systems typically store current state. Your CRM shows who owns an account today, not who owned it when the deal closed six months ago. Your ERP reflects today’s pricing tier, not the tier a customer was on when they churned. Data warehouses preserve this history through change data capture, snapshots, and slowly changing dimension patterns. Without them, an agent cannot answer time-based analytical questions (“How did our retention rate change after the pricing update?”) because the historical state no longer exists in the source. Workarounds like history-tracking tables in your CRM are useful in isolation but do not scale to the entire scope of changes without accruing significant vendor costs and carrying gaps in what has been tracked.
Schema drift. Source system schemas change without warning. A CRM admin renames a field. A SaaS vendor deprecates an API version. A production table adds a column that changes how a join behaves. Data pipelines with schema change detection and contract testing catch these breaks before they reach consumers. An agent connecting directly either fails loudly or, worse, returns results that look right but are wrong because it is interpreting a changed schema with stale assumptions from the last time the model completed training. In a governed data stack, schema drift is a detected, alertable event. In a direct-access model, it is an invisible landmine.
The Economics Do Not Work at Scale
Enterprise SaaS platforms were not built to serve as analytical engines. Salesforce enforces strict API rate limits (100,000 REST API requests per 24 hours on Enterprise Edition, plus a per-user allocation of roughly 1,000). These limits exist because SaaS vendors designed their APIs for transactional integrations, not for the kind of iterative, exploratory querying that analytical agents perform. Cisco has reported that agentic AI workflows can generate up to 25x more traffic than a traditional chatbot interaction, because the agent must reason iteratively (retrieving context, validating assumptions, synthesizing across objects) rather than executing a single pre-defined call.
A single analytical question (“What is the average deal cycle by segment this quarter?”) might require the agent to paginate through opportunity records, pull related account data, retrieve historical stage changes, and cross-reference with a separate system for segment definitions. That is not one API call. It is dozens, possibly hundreds. Scale that across a team and the ceiling arrives fast: requests start returning 429 errors, agents stall mid-analysis waiting for rate limit windows to reset, and the compute time you are paying for on the agent side is wasted on retries. The alternative is purchasing higher API tiers from every vendor whose system the agent touches. These costs compound across systems and as vendors recognize that agentic querying represents a new consumption vector, pricing will tighten further.
Then there is the production database problem. If your agent is issuing analytical queries against a transactional system, you are mixing two fundamentally different workloads. Transactional databases are optimized for high-frequency, low-latency writes: processing orders, updating records, handling user requests. Analytical queries (aggregations, joins across large tables, time-series comparisons) are fundamentally different workloads. Running them against production systems degrades the performance that customers and internal users depend on. The standard architectural response has existed for thirty years: separate your analytical workload into a system designed for it.
OpenAI and Anthropic practice what this principle preaches. OpenAI ingests petabytes of log data daily into a dedicated ClickHouse cluster rather than running analytical queries against production. Anthropic took the same approach after Claude 3’s launch overwhelmed their existing infrastructure. These are the companies building the most capable agents in the world, and they built dedicated analytical infrastructure because the alternative does not work at scale.
A data warehouse solves this by extracting data once, on a governed schedule, and serving unlimited analytical queries against that copy at a fraction of the per-query cost.
Governance and Compliance Cannot Be an Afterthought
When an agent queries a production database directly, who controls what data it can see? How do you audit what it accessed? How do you enforce row-level security across twelve different source systems, each with its own permissioning model?
GDPR requires organizations to demonstrate a lawful basis for processing personal data, enforce data minimization, and honor deletion requests across every system where that data resides. When an agent pulls customer records from your CRM, joins them with support tickets from your helpdesk, and processes the result in memory, you need to know exactly what personal data was accessed, why, and whether it can be traced and deleted on request. Direct source access across a dozen systems makes this nearly impossible to govern.
There is also the question of reproducibility. When a warehouse query produces a number, you can re-run it tomorrow and trace exactly how it was derived. When an agent reasons through five API calls, applies ad hoc logic, and synthesizes an answer, that reasoning path is ephemeral. You cannot hand it to an auditor. You cannot compare this quarter’s number to last quarter’s and guarantee they were computed the same way. A governed data stack makes analytical results reproducible by design. Direct agent access makes them one-off artifacts.
The “Unlimited Cloud Compute” Objection
A common response to some of these concerns is that cloud-hosted agent environments will eventually have enough memory and processing power to handle anything. The local hardware constraint will disappear. This is probably true. It also does not matter.
“Unlimited” still means you are paying for every cycle at cloud rates, and API calls to source systems still cost money. A pre-aggregated table in a data warehouse can answer “What was Q4 revenue by region?” in milliseconds for fractions of a cent. An agent querying five source systems, pulling raw transactional data, joining it in memory, and computing the aggregation will consume orders of magnitude more compute, more API calls, and more time to arrive at the same answer. Multiply that across every question every stakeholder asks, every day, and the cost differential becomes a strategic problem.
When Direct Agent Access Makes Sense
None of this means agents should never query source systems directly. If a question is urgent and an 80/20 answer is acceptable to the audience, trading precision for speed is a reasonable call. If the data involved is small and the person querying is one of a handful of users with permission to access that system, the governance risk is contained. If the analysis is genuinely ad hoc and disposable, a one-time investigation that will never need to be reproduced, the reproducibility concern falls away. And if someone is exploring a new data source to decide whether it is worth integrating into the governed stack at all, direct access is the right starting point.
The danger is not in using agents this way. The danger is in mistaking this mode for a replacement for infrastructure, and making investment decisions on that basis. Direct source access is a useful tool for quick, low-stakes exploration. It is not a foundation for enterprise-grade analytics, reporting, or decision-making.
The Demo Trap
We see this recurring pattern with agentic analytics marketing demos: someone runs a demo where an agent joins a handful of tables and produces a visualization. The data fits in memory. The keys are pre-aligned. There are no edge cases, no schema inconsistencies, no duplicate records, and no access control requirements at that scale. The demo is compelling, and the conclusion drawn is that the data stack (or a specific layer of the stack, like the transformation layer) can be simplified or skipped entirely.
Gartner has predicted that through 2026, 60% of AI projects will be abandoned due to a lack of “AI-ready data”: data that is properly prepared, governed, and integrated at scale. The gap between “it worked in the demo” and “it works reliably at enterprise scale, every day, across all our systems” is the gap that data infrastructure fills.
The missing link is that agents connected to well-modeled data are genuinely powerful. Entity-centric modeling organizes your warehouse around core business entities (customers, products, campaigns, accounts) and enriches them with pre-computed metrics, time-windowed aggregations, and resolved relationships. When that modeling work has been done, an MCP-based agent querying those entities can give end users real self-service analytical capability: ask a question in plain English, get a trustworthy answer, no ticket to the data team required. The agent does not need to guess how to join five tables or infer what “active customer” means, because the entity model has already encoded those decisions. That is the promise the demos are selling, and it is a real promise. It just requires the modeling work to have been done first. The agent is the interface. The infrastructure is what makes the interface reliable.
Final Thoughts
The argument that agents eliminate the need for data infrastructure is analogous to arguing that faster cars eliminate the need for roads. The opposite is true. The faster and more capable the vehicle, the more critical the infrastructure becomes.
My experience is that when organizations skip these foundations, the short-term savings are consumed many times over by the long-term cost of wrong answers, failed audits, production incidents, and lost trust in the data. If your organization is serious about deploying agents at scale, the question is not whether you need data infrastructure. The question is whether you have enough of it.
If your agents are returning inconsistent numbers, if your API costs are compounding faster than expected, or if you cannot explain to an auditor how a figure was derived, the problem is probably not the agent. It is probably the foundation underneath it. If any of this sounds familiar, our AI strategy practice can help you work out what your stack needs. Reach out here.
Sources
- OpenAI internal data stack details (Snowflake, dbt, Airflow, Spark) and the six context layers built for their internal data agent serving 3,500+ employees — based on public disclosures and presentations by OpenAI’s data team
- OpenAI and Anthropic dedicated ClickHouse clusters at petabyte scale for analytical workloads — based on public engineering disclosures from both companies
- Cisco report on agentic AI workflows generating up to 25x more traffic than traditional chatbot interactions — Cisco agentic AI traffic analysis
- Salesforce Enterprise Edition REST API rate limit of 100,000 requests per 24 hours — Salesforce API documentation
- Gartner prediction that through 2026, 60% of AI projects will be abandoned due to lack of “AI-ready data” — Gartner 2025 Hype Cycle research
- GDPR requirements for lawful basis, data minimization, and deletion requests — EU General Data Protection Regulation
For more on this topic, read MCP: What It Costs, Where It Breaks, and When to Use It for the operational side of agent integrations, or listen to What MCP Means for Enterprise Data Strategy and DuckDB: A Game Changer in Data Analytics.


